
redis集群key
发现问题
7月29号, 晚上23:30我们收到kcc报警,我们有个redis集群liveStreamStats内存使用率达到了90%。
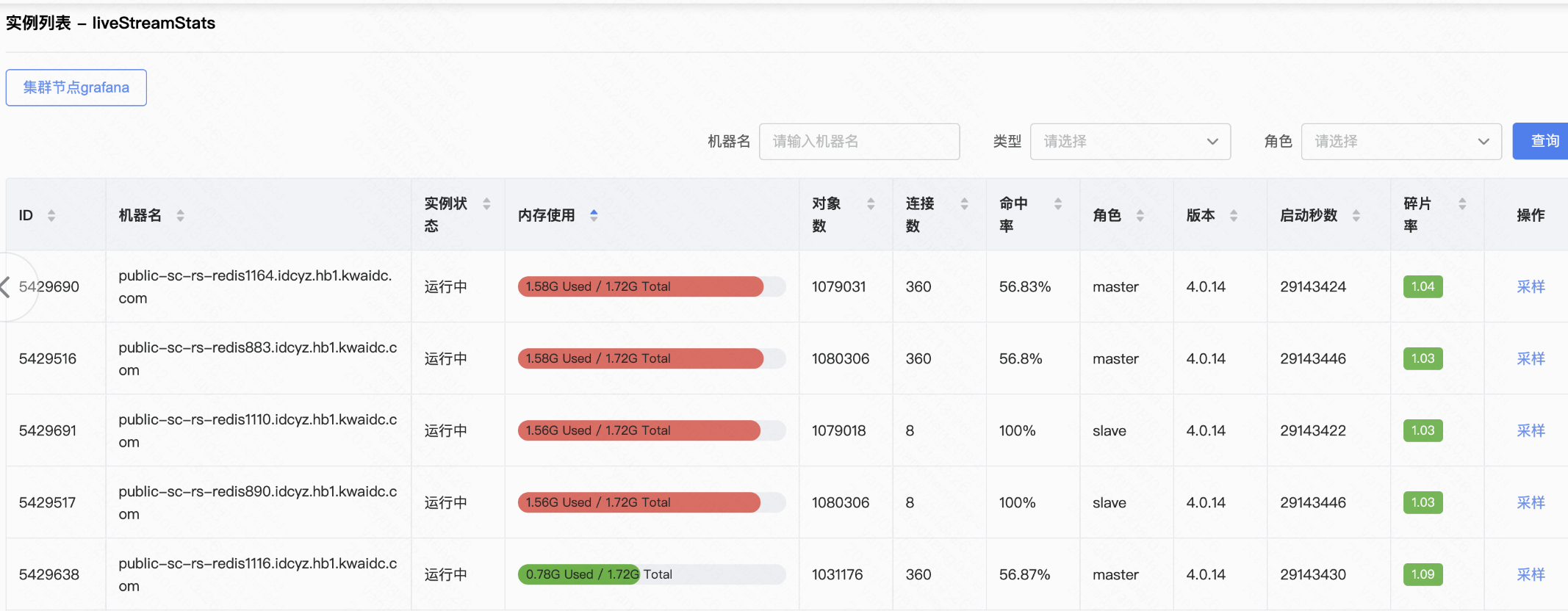
发现有两个redis实例redis使用率到了90%,但是其他的实例内存并没有这么高。
问题止损
因为当时7月29号成龙大哥在开播,并且开播时间是19:50,和监控上内存上涨的时间点吻合,我们怀疑和成龙大哥开播在线人数比较多导致的。当时紧急联系kcc同学垂直扩容了这两台实例。
问题初步定位
当时kcc同学通过解析rdb数据发现以wd_11285866346:(11285866346是成龙大哥的liveStreamId)为前缀的key在这两台实例占的内存最多,对应hash key大概有3w个filed。结合liveStreamStats集群上游服务和成龙大哥在线观众行为,我们怀疑是通过处理观众心跳消息记录观看时长的consumer有数据倾斜或者大key问题,导致liveStreamStats集群中两台实例内存使用率到达90%,通过前缀查看定位到具体代码:
通过代码和redis key确认,确实是这个逻辑有问题。
是否是存在大key问题
可以通过代码看出来,我们记录直播间观众观看时长用的是redis的hash结构,我们在设计这块的时候考虑到,如果一个直播在线人数很大,用一个hash储存会有大key的问题,所以我们在代码中根据userId进行单一大hash结构的拆分。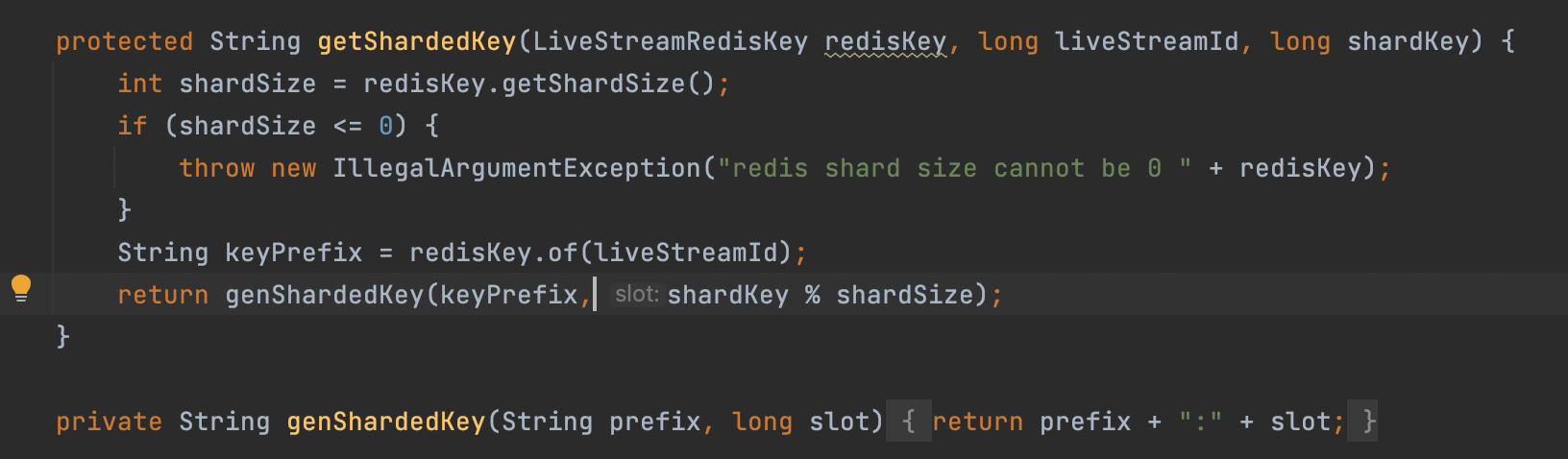
wd_liveid:userid后三位 userid value
从代码上看,我们通过userId分出来了1000个hash,应该不会出现大key的问题,另外结合成龙大哥间內观看人数大概2600w人,1000个hash结构,每个hash有3w左右个filed,每个key数据还是比较均匀的。所以应该不是这个,pass。
是否是有数据倾斜问题
从上面代码来看,业务层通过userId做了hash的拆分,并且key的拼接方式是wd_{liveStreamId}:{0-999}的,按理说kcc-proxy会将每个key均匀的分到每台集群上,不太可能会有数据倾斜呀。我们同时去看了一下之前做的新uv pv服务使用的也是用的这个hash结构,同时就是用的一模一样的拆分逻辑,但是那个集群liveUvPvStatistic没有数据倾斜,但是liveUvPvStatistic集群的实例数是320个节点,liveStreamStats集群是174个节点,我们怀疑proxy的分片是否均匀可能与key的形式和实例个数有关。
问题复现
因为怀疑可能与proxy的分片算法有关,在kcc同学的帮助下,我们得知咱们快手用的redis集群proxy用的是Twitter的twemproxy代理系统,同时咱们快手这边用的key的hash算法是 fnv1a_64(twmproxy默认算法),数据分配方式(distribution)用的是根据key做hash值取模(modula)。同时kcc同学提供了一下fnv1a_64 java版的算法代码,我们基于这个代码写了个测试用例来模拟线上hash key的分片逻辑。
1 | public class LiveFnv1a64Test { |
其中for循环中的0-999模拟genShardedKey(keyPrefix, shardKey % shardSize) shardSize=1000,mcCount模拟redis集群有174台实例。输出的结果如下:
其中modClientCount是指路由到的redis实例个数,modClientmap的key代表路由的对应的redis实例id,value表示对应实例分配redis key个数,我们通过结果发现1000个redis key并没有均匀的分配到174个实例上,只分配了6个,并且其中两台分配了400多个key,和线上的现象一样,有两个实例内存快爆了。
问题推理
现在可以确定就是数据倾斜问题,那么会是key的问题还是机器实例的问题?
为什么这样想问题呢,因为这个redis key分片到哪个实例,可以看做是一个函数
输入:拼装的key & redis实例数
function:是fnv1a_64算法
输出:对应key到实例映射。
所以我们先看看不同的输入会有什么结果
2.redis key的拼装
我们可以发现这个key中的变量是0-999的slot,现在slot的位置在最后,如果在redis实例数不变,我们把slot值弄到中间或者最前面呢会是什么样?
我们分别将key的拼装方式变成:
- 前缀拼接:{0-999}:wd_11285866346
- 中缀拼接:wd_{0-999}:11285866346
- 后缀拼接:wd_11285866346:{0-999}


what!!只有后缀拼接分片特别不均衡,为什么,一会咱们可以通过公式推理一下
问题原因
首先这个问题可以抽象成一下步骤:
1 | 1. 首先一个hash函数对key数组做hash,得出一个int型的hash数组,{h} = hash({key}) |
输入:{key}是key字符串数组,m是redis实例个数。
函数:hash就是fnv1a_64算法
输出:h({h}) 的结果就是映射map,其中{h}就是hash之后的int数组(这个很重要后面推理要用)。
怎么能让key可以更均匀的散列到不同的槽位中,不发生数据倾斜呢?有三种定义:
1 | 1. 如果{h}数列间隔的分布越均匀,那么不管模数为几都会均匀分布,冲突的比较小。 |
第一个方法很好证明,如果hash数组里面的间隔越分散不管模几都均匀,因为分母的数字均匀呀,不管除几求余,后面的余数近似随机。
第二个方法可以简单解释一下,比如一个h({m}) = {m} % n,{m}是有序数组并且间隔一样记作g,间隔数g因子有a b c e,其中n的因子有 a b f g。那么:
m1求模应该是 h(m1) = m1 % n
m2求模应该是 h(m2) = m2 % n = (m1 + g) %n
m3求模应该是 h(m3) = m3 % n = (m1 + 2g) %n
m…求模应该是 h(m..) = m.. % n = (m1 + (..-1)g) %n
g和n有公因子,那么m1%n模出来的是一样的,k*g%n应该模出来的数是一样的,通过模运算的结合律,它们是线性结合,所以总起来模出来的数应该是一样的,从而数列间隔和模数有公因子,则容易发生冲突,且公因子越多。
这个推理不够完备,因为模数的结合律不是简单相加,但是是近似线性,具体可以问一下ChatGPT 4通过概率论和数学推理可以完整的推导出来的,举例论证可以看这篇文章
第三个方法在大学里学数据结构hash的时候老师讲过了,具体的数学推理可以看一下这篇文章
1.redis将int slot放到前缀或者中缀,散列值分布均匀
为什么偏斜呢?
可以看的出来fnv1a_64是种线性算法,它会将输入的数据逐个字符进行处理。
当slot放到后缀的时候,前缀的部分”wd_11285866346:”对散列值的影响在每次key迭代中都是相同的,而只有在最后slot{i}变量相乘时散列值才会不一样,因此slot{i}并不能充分的影响到这个64位的散列值,这就导致了散列值的偏移。
当slot放到前缀或者中间的时候,每次迭代的输入值都是不同的,所以槽变量slot{i}的改变几乎可以在整个64位散列值都有影响,从而使得散列值分布更均匀。
2.redis实例数如果是素数和2的n次方,散列值分布均匀
在slot为后缀的时候,为什么模数是174偏移这么严重
先解释一下实例数是174的时候,为什么偏移这么严重。
根据定义二,hash数列间隔和模数有公因子,则容易发生冲突,且公因子越多,冲突的可能性越多。那我们现在先看一下hash数列间隔是怎么分布的。先写一个测试用例看一下hash数列间隔分布如下:
其中gapList是hash数列间隔的List,gapGroupMap是hash数列间隔分布情况,咱们可以debug一下:
可以发现一共999个间隔,其中间隔为435的就占有825个。为什么间隔数有这么多435,算法中*435。
435的因数为
1 | 435 = 3 *5 * 29 |
174的因数为
1 | 174 = 2 * 3 * 29 |
hash数列间隔435和模数174个公因子有两个,所以分片出来的key有数据倾斜。
在slot任意,为什么模数是素数比较均匀
这个前面解释过了,不在这里赘述了,具体的数学推理可以看一下这篇文章
在slot任意,为什么模数是2的指数幂比较均匀
在理解174为啥偏移严重的基础上,我们可以很简单的知道&
435的因数为
1 | 435 = 3 *5 * 29 |
2的指数幂的因数都是2的倍数,所以他们没有公因数,从而比较均匀,没有什么偏移。
解决方案
如果业务中用的key拼接策略是将slot拼接到后缀,并且redis实例数如果不是素数或者2的指数幂,redis集群就有可能出现严重的数据倾斜。所以解决方案如下:
1.将redis key的拼接规则改成slot数字作为前缀或者中缀
2.在申请redis集群时,可以将集群个数设置2的n次方
虽然实例数为素数,数据分布比较均匀,但是素数基本是奇数结尾,kcc在分配集群机器时不太好分配,所以最好不要用素数作为实例数。